$ sudo service docker start
Redirecting to /bin/systemctl start docker.service
Job for docker.service failed because the control process exited with error code. See "systemctl status docker.service" and "journalctl -xe" for details.
이는 URL의 범위가 어디까지 인가에 대한 혼란인 것 같다. RFC1737에 따르면 PATH, 쿼리스트링 모두 URL에 포함된다.
httpaddress http://hostport[/path][?search]
이런 혼란이 생긴 이유중에 하나로 HttpServletRequest의 잘못도 있다고 생각한다.
@GetMapping("/user")
public void test(HttpServletRequest request, @RequestParam("id") int id) {
String uri = request.getRequestURI();
String url = request.getRequestURL().toString();
logger.info("uri - {}, url - {}", uri, url);
}
로그를 찍어보면 아래와 같이 나온다. uri - /user, url - http://localhost:8080/user
이걸보고, '아 url에 쿼리스트링은 포함되지 않는구나' 에 더불어 'uri는 path 부분을 말하는구나' 라고 착각할 수 있을 것 같다.
HttpServletRequest의 문서를 읽어보면
getRequestURI public java.lang.String getRequestURI() Returns the part of this request's URL from the protocol name up to the query string in the first line of the HTTP request. The web container does not decode this String. For example: First line of HTTP request Returned Value POST /some/path.html HTTP/1.1 /some/path.html GET http://foo.bar/a.html HTTP/1.0 /a.html HEAD /xyz?a=b HTTP/1.1 /xyz To reconstruct an URL with a scheme and host, use HttpUtils.getRequestURL(javax.servlet.http.HttpServletRequest).
Returns: a String containing the part of the URL from the protocol name up to the query string See Also: HttpUtils.getRequestURL(javax.servlet.http.HttpServletRequest)
getRequestURI()는 URL(URL은 URI이므로)의 일부분(path)만 리턴한다고 되어있고, 전체 URL을 얻고 싶으면 다른 방법을 쓰라고 되어있다. getRequestURI()의 리턴값 /user 은 URL의 일부일 뿐, URL은 아니다. method명이 혼란을 주는 듯 하다.
getRequestURL public java.lang.StringBuffer getRequestURL() Reconstructs the URL the client used to make the request. The returned URL contains a protocol, server name, port number, and server path, but it does not include query string parameters. Because this method returns a StringBuffer, not a string, you can modify the URL easily, for example, to append query parameters.
This method is useful for creating redirect messages and for reporting errors.
Returns: a StringBuffer object containing the reconstructed URL
여기서는 또 URL에서 쿼리스트링을 빼고 리턴하겠다고 한다. 때문에 쿼리스트링은 URL이 아닌 것 처럼 혼란을 주는 것 같다. getRequestURL()의 리턴값 http://localhost:8080/user은 URL의 일부일 뿐, URL은 아니다.
결론
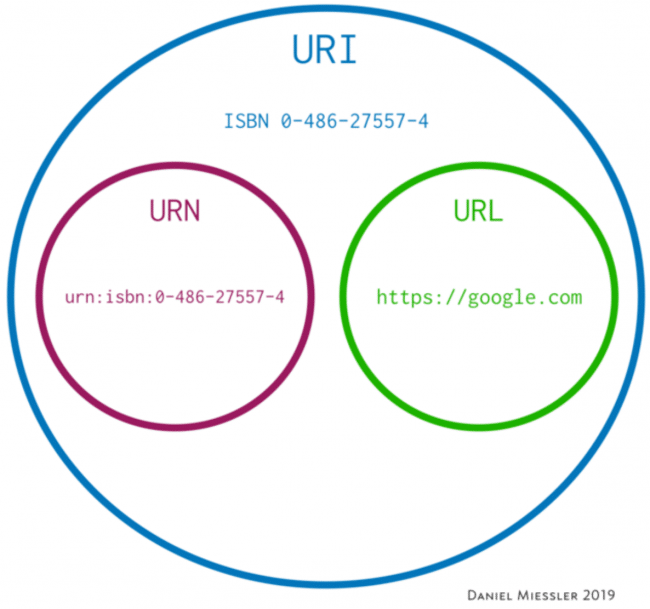
URI는 리소스 식별자이다.
URL은 리소스를 어디서 얻을 수 있는 지 위치를 말해준다. URL는 식별방법의 일부이다.
또 다른 식별방법으론 고유한 이름을 부여하는 URN이 있다.
Appendix
RFC says
A URI can be further classified as a locator, a name, or both. The term “Uniform Resource Locator” (URL) refers to the subset of URIs that, in addition to identifying a resource, provide a means of locating the resource by describing its primary access mechanism (e.g., its network “location”). rfc 3986, section 1.1.3
URI는 위치, 이름 등이 될 수 있다.
The URI itself only provides identification; access to the resource is neither guaranteed nor implied by the presence of a URI. rfc 3986, section 1.2.2
URI는 식별만 할 뿐, 리소스를 어디서 얻을 수 있는지를 반드시 제공해야하는 것은 아니다.
Each URI begins with a scheme name, as defined in Section 3.1, that refers to a specification for assigning identifiers within that scheme. rfc 3986, section 1.1.1
OAuth는 인증보단 인가 목적의 표준이므로 SAML과 OIDC를 비교해보자. SSO과 같이 통합인증(federated authentication)을 위해 SAML이 있었다. 그런데 단점이 있다. SAML은 클라이언트가 웹사이트인 경우에는 적합하지만 모바일 어플리케이션 등에는 적합하지 않다. (그 이유는 아래에서) 이런 단점들을 OAuth 프로토콜을 이용해 보완하게 OIDC이다.
SAML(Security Assertion Markup Language)과 OIDC
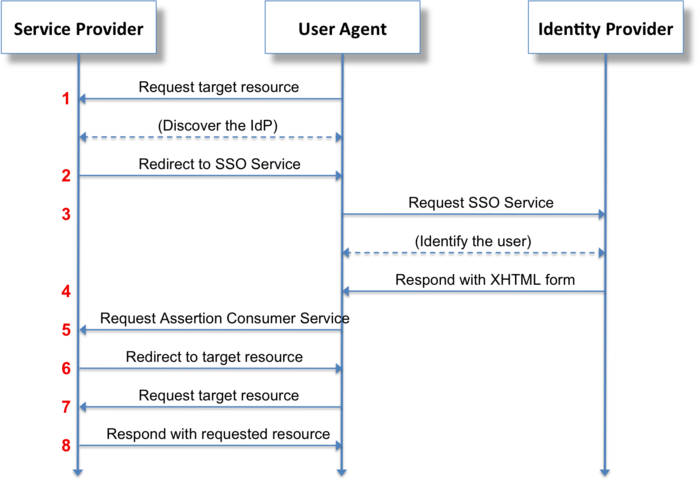
SAML 인증 플로우
SAML은 SP가 웹 사이트여야만 한다. OIDP는 웹이나 모바일앱 등이 가능하다.
SAML은 백채널을 (거의) 안쓴다. 브라우저를 통해서만 SP와 IDP가 인증정보를 주고 받는다. 서버간 통신없이 클라이언트를 통해서 인증 데이터를 주고 받기 때문에, POST 바인딩을 통해 인증정보 + 리다이렉션을 처리한다. ( POST Binding) 헤더를 사용하는게 아니라 HTML내에 스크립트를 심어서 리다이렉트를 시키기 때문에 클라이언트가 웹사이트여야 한다. 모바일웹에서 SAML 방식을 사용한다고 하면 별도로 브라우저를 띄워서 구현해야 할 텐데 그럼 사용자 경험이 떨어질 것이다.
IDP의 응답으로 내려온 HTML에서 스크립트로 리다이렉트 처리하는 예시이다. form으로 POST 요청을 만들어 IDP에서 얻은 인증 정보를 SP에게 전달한다. 스크립트가 실행되기 위해선 브라우저라는 환경이 필요하다.
OAuth2.0은 3rd Party의 API 사용인가가 목적이고, OIDC는 통합인증(federated authentication), SSO가 목적이다. (OAuth를 인증 용도로도 사용할 수는 있다)
OAuth를 인증 용도로 사용할 수 있는데 왜 OIDC가 필요한걸까?
OAuth는 다양한 상황의 요구사항을 충족할 수 있또록 제네릭하게 구현되었다. 제네릭하다는 것은 그 만큼 클라이언트에서 할일이 많아진다. 반면 OIDC는 인증 초점이다. 상대적으로 클라이언트가 간편하게 사용할 수 있다. 또한 OAuth에서 제공하지 않는 부가적인 스펙(OP Discovery 등)도 있다. 때문에 인증만이 목적이라면 OIDC를 사용하는게 좋을 것 같다.
OIDC에는 id_token 개념이 추가된다. 사용자에 대한 부가적인 정가 id_token에 담긴다. 사용자 정보를 얻기 위해 별도 API콜을 하지 않아도 된다. (요청량이 많은 서비스에선 유의미한 효과일 것이다)
Publisher와 Subscriber가 독립적으로 데이터를 생산하고 소비한다. 프로듀서와 컴포넌트를 디커플링하기 위한 좋은 수단이다.
이런 느슨한 결합을 통해 둘 중 하나가 죽어도 서로간에 의존성이 없으므로 안정적으로 데이터를 처리할 수 있다.
리시버와 컬렉터의 통신을 API로 한다고 가정해보자.
컬렉터는 리시버가 요청한 것을 바로 처리해줘야 한다. (처리를 미룰 수 없다)
실패가 났을 때 부분 재처리가 불가능하다.
처리속도가 느린 컴포넌트 기준으로 처리량이 결정된다. 그러므로 트래픽이 몰리는 상황을 대비해 전체 파이프라인을 넉넉하게 산정해야 한다.
중간에 카프카를 두게 되면 이런게 좋아진다.
컬렉터는 리시버가 요청한 작업을 쌓아두고 나중에 처리할 수 있다.
실패가 나도 컬렉터만 따로 재처리 할 수 있다.
일시적으로 트래픽이 몰리는 상황을 대비해서 제일 프론트의 서버만 넉넉하게 준비해두면 된다. 물론 장기적이 되면 전체 파이프라인을 증설해야 겠지만.
또한 설정 역시 간단해진다.
Publisher 따로, Consume 따로 독립적으로 설정할 수 있다.
디스크 순차 저장 및 처리
메시지를 메모리큐에 적재하면 데이터 손실 가능성이 있지만 카프카는 디스크에 쓰므로 데이터 손실 걱정이 없다.
디스크에 쓰므로 상대적으로 속도가 느리지만, 순차처리 방식으로 디스크 I/O를 줄여 그렇게 느리지도 않다. 엄청 반응성이 높은 서비스가 아니라면 이 속도가 문제되진 않는다.
카프카 아키텍처 구성요소
토픽
카프카 안에는 여러 레코드 스트림이 있을 수 있고 각 스트림을 토픽이라고 부른다.
하나의 토픽에 대해 여러 Subscriber가 붙을 수 있다.
파티션
각 토픽마다 데이터를 여러개의 파티션에 나누어서 저장/처리한다.
토픽 사이즈가 커질 경우 파티션을 늘려서 스케일아웃을 할 수 있다.
일반적으로 브로커 하나당 파티션 하나다.
컨슈머 인스턴스 수는 파티션 갯수를 넘을 수 없다. 그러므로 병렬처리의 수준은 파티션 수에 의해 결정된다. 즉 파티션이 많을 수록 병렬처리 정도가 높아진다.
각 파티션마다 Publish되는 레코드에 고유 오프셋을 부여한다. 때문에 레코드는 파티션 내에서는 유니크하게 식별된다. 하지만 파티션간에는 순서를 보장하지 않는다.
전체 순서를 보장하고 싶으면 파티션을 하나만 두는 수 밖에 없는데, 이러면 데이터량이 많아져도 스케일아웃이 안되고, 컨슈머 인스턴스도 하나만 둘 수 있으므로 병렬 컨슈밍도 안된다.
데이터 보관기간
컨슘하고는 상관없다. 보관기간(Retention) 정책에 따른다.
데이터 사이즈가 늘어날지라도 성능은 일정하게 유지된다.
오프셋
일반적으로 컨슈머가 오프셋을 순차적으로 증가하며 컨슘해하지만, 원한다면 컨슈머 마음대로 조정할 수 있다. 재처리가 필요한 경우 오프셋을 이전으로 돌릴 수도 있고 가장 최근 레코드 부터 처리할 수도 있다.
컨슈밍 비용이 저렴하기 때문에 커맨드라인 컨슈머로 데이터를 "tail"하는 작업도 다른 컨슈머에 별 영향을 끼치지 않는다.
프로듀서
레코드를 프로듀스할 때 어느 토픽의 어느 파티션에 할당할 지를 결정한다.
일반적으로 라운드로빈 혹은 원하는 대로 할당방식을 지정할 수 도 있다.
컨슈머 그룹
컨슈머 그룹 마다 독립적인 컨슘 오프셋을 가진다.
컨슈머 그룹 내에서 처리해야할 파티션이 분배된다. 즉 하나의 파티션은 하나의 서버가 처리한다. 그룹에 서버가 추가되면 카프카 프로토콜에 의해 동적으로 파티션이 재분배 된다.
하나의 토픽 레코드를 분산처리하는 구조라면 동일 컨슈머 그룹을 가지게 해야 한다.
하나의 토픽 레코드에 각각 별도의 처리를 하는 다른 파이프라인이라면 서로 다른 컨슈머 그룹을 가지게 해야 한다.
큐(Queue)와 Pub/Sub의 혼합 모델
컨슈머그룹 내에서는 큐처럼 동작하고 컨슈머그룹간에는 Pub/Sub처럼 동작한다. 컨슈머그룹을 어떻게 두냐에 따라 두 방식 다 입맛에 맞게 선택할 수 있다.
데이터 순서 보장
일반적인 큐 모델에서 순차적으로 컨슘해간다고 해도 각 처리기에 도달하는 시간이 다르므로 순서가 보장되지 않는다.
그렇다고 처리기를 1개만 두면 병렬성이 떨어진다.
카프카는 토픽의 전체 순서는 보장하지 않지만 파티션별로는 처리 순서를 보장한다. (파티션은 하나의 컨슈머 인스턴스에서만 처리되므로). 즉 전체 순서 보장을 포기하고 부분 순서 보장을 취한 것이다. 대신 병렬성을 유지할 수 있다. 다르게 말하면 파티션당 컨슈머를 하나만 가져야하는 이유는 파티션 내에서 처리순서를 보장하기 위함이다.
데이터 복제
각 파티션을 여러대의 서버에 복제해둔다. 이는 설정값을 따른다. 크래시리포트는 ?개의 리플케이션을 두었다.
각 파티션 마다 특정 서버 한대를 리더로 선정하고 나머지 복제 파티션은 팔로워가 된다.
리더가 모든 읽기/쓰기를 처리한다. 리더는 요청을 패시브하게 팔로워들에게 전파한다.
각 서버는 하나의 리더 파티션을 갖는다. 때문에 트래픽은 각 서버로 밸런싱이 되는 셈이다.
복제 수가 N개라면 N-1개까지 죽어도 실패복구가 가능하다.
주키퍼의 역할
컨트롤러를 선출한다. 컨트롤러는 전체 파티션에 대한 리더/팔로워를 관리한다. 컨트롤러의 역할은 노드가 죽으면 다른 리플리카에게 리더가 되라고 명령을 내리는 역할을 한다.
어떤 브로커가 살아있는지를 체크한다.
어떤 토픽이 있고, 토픽에 파티션이 몇개 있고, 리플리카는 어디있고, 누가 리더가 될만한지, 각 토픽에 어떤 설정이 되어있는지를 관리한다.
오프셋 관리
카프카에서 관리하는 오프셋은 두 종류가 있다.
Current Offset : 컨슈머에게 전송된 마지막 레코드의 포인터
Committed Offset : 컨슈머가 성공적으로 처리한 마지막 레코드의 포인터.
오프셋 커밋 방법
카프카에서 관리되는 방식 : _consumer_offsets 토픽에 오프셋이 저장된다.
오토 커밋 : 일정 주기를 가지고 자동으로 커밋한다. 작업이 끝났든 안끝났든 주기만 되면 커밋한다.
커밋되기 전에 리밸런싱이되면 중복처리가 발생한다.
처리 완료되기 전에 커밋 후 프로세스가 죽으면 데이터 손실이 발생한다. (at-least-once 보장X)
수동 커밋 : 수동으로 커밋 API를 호출한다. 정확히 작업이 끝나고 커밋하는 걸 보증하기 위해 사용한다.
커밋되기 전에 리밸런싱되면 중복처리가 발생한다.
자체적으로 관리하는 방식 : 별도 DB등에 자체적으로 오프셋을 관리한다.
메시지 보증 전략
일반적인 보증 전략은 다음과 같고 카프카는 at-least-once로 보증한다.
at-most-once : 중복X, 유실O
exactly-once : 중복X, 유실X, 구현하기 어렵다.(비용이 비싸다)
at-least-once : 중복O, 유실X
데이터가 중복되는 경우는 다음과 같다. 어떤 데이터가 poll됐으나 commit되지 않은 시점에 리밸런싱 작업이 일어나면 이미 poll되어서 처리중인 데이터를 다른 컨슈머가 또 poll갈 수 있다.
수동 커밋에서도 마찬가지다. 커밋 전에 리밸런싱이 되는 경우 중복으로 처리될 수 있다.
가장 좋은건 exactly-once지만 비용이 비싸므로 적당한 타협지점은 at-least-once이다.중복되는 메시지는 메시지 ID나 시간등으로 어느정도 보정이 가능하기 때문이다.
카프카 0.11 버전 부터 idempotent producer와 tracsaction producer의 등장으로 exactly-once를 보장할 수 있다고 한다.
내부적으론 레코드의유니크ID, 트랜잭션ID, 프로듀서ID등을 조합해서 처리한다고 한다.
크래시리포트의 오프셋 관리
스파크 클러스터만 수동커밋을 하고 있다. 스파크는 보통 poll에서 프로세싱 완료까지 시간이 오래걸릴 것으로 예상되므로 오토커밋을 할 경우 데이터 손실 가능성이 커서 수동으로 커밋하는 걸로 보인다.
오프셋을 카프카가 아닌 별도의 DB에 저장했다. commitAsync()에서 fail이 발생했던 거 같은데 정확한 원인은 모르겠다.
다른 미들웨어와 비교해보자.
RabbitMQ
장점
다양한 기능, 높은 성숙도
20k/sec 처리 보장
Kafka
장점
고성능 고가용성
분산처리에 효과적으로 설계됨
100k/sec 처리 보장
겪었던 이슈들
ERROR [Thread-20] [Consumer clientId=consumer-13, groupId=xxx-collector] Offset commit failed on partition zxx.topic-1 at offset 199: The request timed out.
HTML attribute names are case-insensitive, so browsers will interpret any uppercase characters as lowercase. That means when you’re using in-DOM templates, camelCased prop names need to use their kebab-cased (hyphen-delimited) equivalents: