'URI가 URL을 포함한다' 정도만 알고 있었는데, 제대로 정리해보고자 한다.
URI, URL, URN의 개념
모두 리소스 식별자이다.
리소스를 구분하고 싶은 것이다.
예를 들어 어떤 두 사람이 있다고 치자.
두 사람을 구분하고 싶다.
어떻게 구분할까?
이름을 붙인다. --> URN
첫번째 사람 - 홍길동,
두번째 사람 - 박길동그 리소스를 얻을 수 있는 주소(위치)를 표현한다. --> URL
첫번째 사람 - 서울시 아무구 아무동 123-1
두번째 사람 - 서울시 아무구 아무동 456-1
이러한 방법으로 리소스를 명확히 식별할 수 있으면(구분할 수 있으면) 그건 URI다.
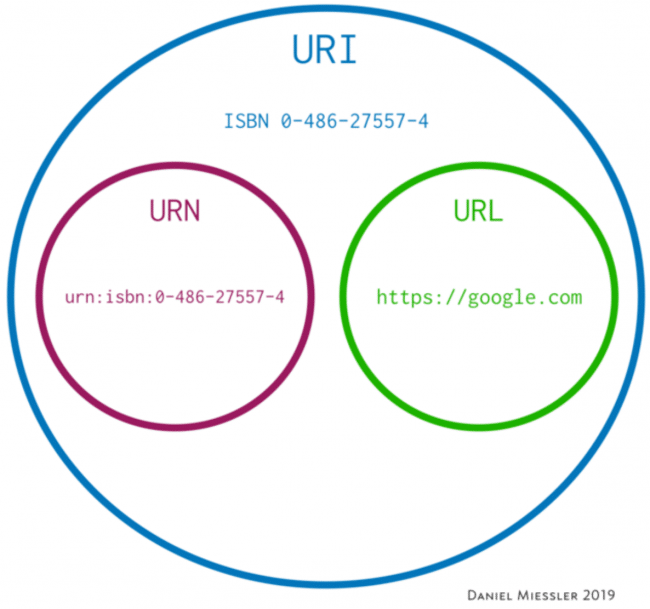
따라서 URN(Uniform Resource Name) 과 URL(Uniform Resource Locator) 모두 URI(Uniform Resource Identifier)다.
여기서 하나씩 짚고 넘어가보자.
URN이란?
리소스에 고유한 이름을 부여해서 구분하겠다는 방식이다.
여기서 중요한건 고유해야한다는 것이다.
예를 들어 urn:isbn:0-486-27557-4 를 검색하면 로미오와 줄리엣이 나온다.
ISBN은 국제표준도서번호이고, 국제표준으로 도서에 고유한 이름 을 부여한 것이다.
이건 서로 약속하는 것이다. 중복이 없어야 한다.
그런데 여기서 URL과 차이가 있다.
URN은 리소스를 식별만 할뿐 리소스를 얻을 수 있는 위치는 포함하지 않는다
리소스 위치에 상관 없이 고유하게 식별하려는 목적이다.
URL이란?
리소스를 식별하는 방법 중에, 리소스의 위치로 식별하는 방법이다.
ex) https://tools.ietf.org/html/rfc1738 --> 이 URL로 특정 RFC문서(리소스)를 얻을 수 있다.
ex) https://somewhere.com/user?userId=123 --> 이 URL로 특정 유저 정보(리소스)를 얻을 수 있다.
리소스를 위치 로 식별하겠다는 것이다.
URN과 비교를 해보자.
https://book.com/romio-juliet
https://book.net/romio-juliet
둘 다 동일한 로미오와 줄리엣 리소스를 가리킨다고 했을 때 URL은 각각을 서로 다른 리소스로 식별한다.
중간 정리
리소스 식별자 --> URI = URN + URI + α
이름으로 식별 --> URN
위치로 식별 --> URL
혼란
관련해서 구글링을 해보면 URL의 정의에 대한 여러 의견이 있어 혼란스러운 부분이 있었고, 이를 나름대로 정리해보고자 한다.
어디까지 URL인가
아래와 같이 정리된 글이 있었다.
https://somewhere/search?q=uri 아래와같은 주소가 있다고하자. query string인 q의 값에 따라 여러가지 결과값을 가져올 수 있다. 위 주소에서 URL은 https://somewhere/search까지이고, 내가 원하는 정보를 얻기위해서는 q=uri라는 식별자가 필요하므로, https://somewhere/search?q=uri 이 주소는 URI이지만 URL은 아니다.
아니다. 쿼리스트링까지 있어야 리소스를 명확히 식별할 수 있으므로 https://somewhere/search?q=uri이 URL이고 URI다. 쿼리스트링도 URL에 포함된다.
또 다른 글이 있었다.
아니다. 정확히 132에 해당하는 리소스를 식별해야하므로 http://somewhere.com/132 까지가 URL이다.
물론 http://somewhere.com에 해당하는 리소스가 있으면 http://somewhere.com 자체도 URL이지만 132에 대한 URL은 http://somewhere.com/132인 것이다.
이는 URL의 범위가 어디까지 인가에 대한 혼란인 것 같다.
RFC1737에 따르면 PATH, 쿼리스트링 모두 URL에 포함된다.
httpaddress http://hostport[/path][?search] 이런 혼란이 생긴 이유중에 하나로 HttpServletRequest의 잘못도 있다고 생각한다.
@GetMapping("/user")
public void test(HttpServletRequest request, @RequestParam("id") int id) {
String uri = request.getRequestURI();
String url = request.getRequestURL().toString();
logger.info("uri - {}, url - {}", uri, url);
}로그를 찍어보면 아래와 같이 나온다.uri - /user, url - http://localhost:8080/user
이걸보고, '아 url에 쿼리스트링은 포함되지 않는구나' 에 더불어 'uri는 path 부분을 말하는구나' 라고 착각할 수 있을 것 같다.
HttpServletRequest의 문서를 읽어보면
getRequestURI
public java.lang.String getRequestURI()
Returns the part of this request's URL from the protocol name up to the query string in the first line of the HTTP request. The web container does not decode this String. For example:
First line of HTTP request Returned Value
POST /some/path.html HTTP/1.1 /some/path.html
GET http://foo.bar/a.html HTTP/1.0 /a.html
HEAD /xyz?a=b HTTP/1.1 /xyz
To reconstruct an URL with a scheme and host, use HttpUtils.getRequestURL(javax.servlet.http.HttpServletRequest).
Returns:
a String containing the part of the URL from the protocol name up to the query string
See Also:
HttpUtils.getRequestURL(javax.servlet.http.HttpServletRequest)
getRequestURI()는 URL(URL은 URI이므로)의 일부분(path)만 리턴한다고 되어있고, 전체 URL을 얻고 싶으면 다른 방법을 쓰라고 되어있다.
getRequestURI()의 리턴값 /user 은 URL의 일부일 뿐, URL은 아니다. method명이 혼란을 주는 듯 하다.
getRequestURL
public java.lang.StringBuffer getRequestURL()
Reconstructs the URL the client used to make the request. The returned URL contains a protocol, server name, port number, and server path, but it does not include query string parameters.
Because this method returns a StringBuffer, not a string, you can modify the URL easily, for example, to append query parameters.
This method is useful for creating redirect messages and for reporting errors.
Returns:
a StringBuffer object containing the reconstructed URL
여기서는 또 URL에서 쿼리스트링을 빼고 리턴하겠다고 한다.
때문에 쿼리스트링은 URL이 아닌 것 처럼 혼란을 주는 것 같다.
getRequestURL()의 리턴값 http://localhost:8080/user은 URL의 일부일 뿐, URL은 아니다.
결론
- URI는 리소스 식별자이다.
- URL은 리소스를 어디서 얻을 수 있는 지 위치를 말해준다. URL는 식별방법의 일부이다.
- 또 다른 식별방법으론 고유한 이름을 부여하는 URN이 있다.
Appendix
RFC says
A URI can be further classified as a locator, a name, or both. The term “Uniform Resource Locator” (URL) refers to the subset of URIs that, in addition to identifying a resource, provide a means of locating the resource by describing its primary access mechanism (e.g., its network “location”).
rfc 3986, section 1.1.3
URI는 위치, 이름 등이 될 수 있다.
The URI itself only provides identification; access to the resource is neither guaranteed nor implied by the presence of a URI.
rfc 3986, section 1.2.2
URI는 식별만 할 뿐, 리소스를 어디서 얻을 수 있는지를 반드시 제공해야하는 것은 아니다.
Each URI begins with a scheme name, as defined in Section 3.1, that refers to a specification for assigning identifiers within that scheme.
rfc 3986, section 1.1.1
참고자료
https://danielmiessler.com/study/difference-between-uri-url/
https://tools.ietf.org/html/rfc1738
'개발 > 기타' 카테고리의 다른 글
| Docker service 실행 안될 때 (0) | 2022.04.05 |
|---|---|
| [SpringSecurity] Https same origin 에 대한 CORS 설정 (0) | 2020.06.09 |
| SAML / OAuth2.0 / OpenIDConnect (1) | 2020.05.12 |
| [PHP] Call to undefined function dl() (0) | 2020.02.10 |
| 카프카(Kafka) (0) | 2020.01.30 |