Java에서 프리미티브(Primitive) 타입 및 String 객체는 불변 속성이 있다.
음... String 객체는 알겠는데, 프리미티브 타입도 불변하다고 말할 수 있는건가? 하는 의문이 들었고 이것부터 짚고 넘어가고자 한다.
불변(Immutable)의 개념
최초 생성 이후로는 상태(속성)를 변경할 수 없는 성질
String 클래스를 예로 들어보자. Java에서 String은 불변하게 구현되어 있기 때문에 + 연산을 하더라도 초기 생성 이후로는 객체를 수정할 수 없다.
String str = "a";
str += "b";
초기 상태. String str = "a"재할당. str += "b"
기존에 0xAB에 있던 String에 "b"를 추가하는게 아니라 새로운 "ab" 객체를 만들고 str이 해당 객체를 참조하도록 레퍼런스를 변경하고 있다.
Java에서 불변 속성을 이야기 할 때는 객체에 대한 것이고. 객체가 아닌 프리미티브 타입에 대해선 불변(Immutable)인가 아닌가를 이야기 하기가 어렵다.
왜 프리미티브 타입에 대해선 불변 속성을 따지기가 어려운가
프리미티브 타입은 레퍼런스로 참조되지 않고 변수에 직접 값을 가지고 있다. int 연산을 예로 들면, 다음과 같다.
불변하다는 것은 어떤 것(Identity)의 속성을 바꿀 수 없는 것을 말하는데, int a에는 속성이랄게 없다. 객체는 명확히 속성이 있다. String 객체는 자신의 char[] 속성을 가지고 있고, 이 char[]을 변경할 수 없기에 immutable 하다고 한다. int a는 속성이 없다. a는 그 자체로 값이다. 다시 말해 Identity가 곧 value이다. 새로운 연산이 일어날 때 마다 새로운 값(새로운 Identity)로 교체된다. Immutable은 Identity와 속성의 구분이 있어야 적용할 수 있는 개념으로 생각된다.
왜 불변 속성이 필요한 걸까?
우선 왜 Java에서 String을 불변하게 구현했는지 부터 찾아봤다.
메모리 절약 String은 광범위하게 사용되는 객체이다. 같은 값을 갖는 경우 기존 객체를 재사용하여 힙 메모리 공간을 절약할 수 있다.
String이 불변하지 않다면 str1, str2 각각 객체를 생성해야겠지만, 불변하기 때문에 같은 객체를 바라봐도 무방하다.
String str1 = "a";
while(...) {
str1 += "a";
}
그러나 위 코드와 같이 String값을 변경하는 연산이 많은 경우, 10만번 연산을 한다고하면, 10만개의 객체가 생성되므로 이런 경우에는 주의해야 한다. 이 경우엔 StringBuffer를 사용하는 것이 좋다. StringBuffer는 불변이 아닌, 힙에 할당된 버퍼의 크기를 늘이거나 줄이면서 동작하기 때문에 실제 메모리에 객체가 1개만 생성된다.
성능 향상 String은 매우 자주 사용되는 객체이고, HashMap, HashTable, HashSet 등에서 해시코드 계산도 그만큼 많을 것이다. String의 불변 속성으로 인해 최초 한번간 hashCode() 연산이 수행되고 이후에는 캐싱된 값을 리턴하게 되어 성능에서 이득이 있다.
Thread-safe 상태를 가지는 객체가 여러 스레드에 의해 공유될 때 문제가 생긴다. 이럴 때 사용하는 동기화 기법이 여러가지가 있는데, 예를 들면 lock을 건다던가 등이다. 불변 속성은 동기화 기법은 아니지만 객체를 Read-only로만 제공함으로써 상태를 변경하는 행위를 원천적으로 차단한다. 쓰기 기능을 포기하는 대신 Thread-safe 장점을 얻어간다고 볼 수 있다.
Java는 플랫폼에 독립적으로 동작하기 위해 CPU에서 직접 instruction을 수행하지 않는다.
대신 pc 레지스터라는 별도의 메모리공간를 두고 이를 이용해 instruction을 수행한다.
pc 레지스터에는 현재 실행중인 JVM instruction이 저장된다. 네이티브 메서드의 경우는 JVM에서 실행되지 않으므로 undefined값을 가지게 된다.
스레드 마다 pc 레지스터를 가진다.
스택
스레드마다 스택을 가진다. 다른 스레드의 스택영역엔 접근 할 수 없다.
메서드가 호출될 때 마다 스택에 새로운 프레임들이 생성되고 메서드 종료 시 스택에서 제거된다.
스택은 고정사이즈일 수도 있고 동적으로 사이즈를 확장할 수도 있다.
스택의 메모리 부족과 관련된 두가지 종류의 에러가 있다.
StackOverflowError - 고정 사이즈의 스택에서 지정된 사이즈를 초과할 경우 발생
OutOfMemoryError - 다이나믹 사이즈 스택에서 메모리가 부족할 경우 발생
힙
모든 스레드가 접근할 수 있다.
프리미티브 타입이 아닌 데이터들이 저장되는 영역이다. 클래스 인스턴스, 배열 등이 포함된다. 메모리 관리에 대한 스펙은 규정되어있지 않고 벤더사가 알아서 구현하도록 되어있다.
힙 영역 메모리은 인접해있지 않아도 된다. 힙 영역이 부족해지만 OutOfMemoryError가 발생한다.
메서드 영역(Method Area)
모든 스레드가 접근할 수 있다.
코드들이 저장된다고 볼 수 있다.
클래스의 런다임상수풀, 필드, 메서드 데이타, 메서드 코드, 생성자와 같은 것들을 저장한다.
JVM의 시작될 때 같이 생성된다. 논리적으론 힙에 속하지만 가비지 컬렉션을 한다던가 하는 건 벤더사에 맡기고 있다.
고정사이드 혹은 런타임에 확장 가능한 사이즈를 갖기도 한다.
이 영역의 메모리가 부족해지만 OutOfMemoryError가 발생한다.
보충자료
프레임이란?
메서드가 호출될 때 마다 새로운 프레임이 생성된다. 메서드 종료 시 스택에서 제거되며 리턴값을 이전 프레임에게 전달한다.
다이나믹 링킹, 메서드 리턴값, 디스패치 익셉션과 같은 데이터를 저장하기 위해 사용된다.
프레임은 아래와 같이 구성된다.
로컬 변수 메서드의 지역변수를 배열 형태로 저장한다. 프리미티브 타입의 값은 스택에 같이 저장되고, 레퍼런스 타입은 실제 값은 힙영역에 있고 그 힙영역의 주소값을 스택에 저장한다.
오퍼랜드(Operand) 스택 계산을 위한 입출력 데이터를 저장하는 공간이다.
런타임상수풀(Run-time constant pool) 레퍼런스 프레임마다 런타임상수풀(Run-time constant poo) 레퍼런스를 포함하고 있다. 심볼릭 링크 형태의 메서드/변수를 참조하는 경우 런타임상수풀을 참조하여 실제 로드된 스트럭처의 오프셋 형태로 변환한다. 런타임상수풀을 사용함으로써 동적 로딩이 가능해진다.
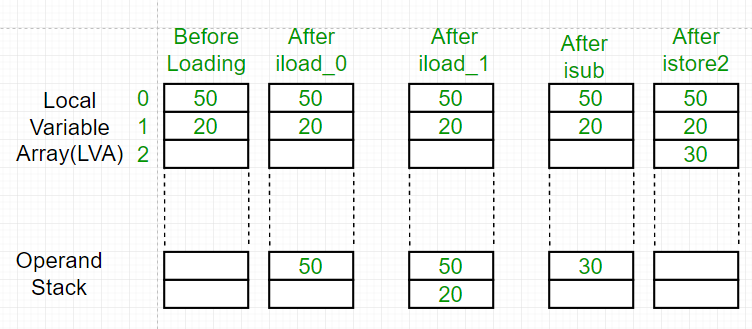
프레임의 로컬 변수와 오퍼랜드 예제
public int add(int a, int b) {
int c = a + b;
return c;
}
이 코드의 바이트 코드는 다음과 같다
Code:
stack=2, locals=4, args_size=3
0: iload_1 # 지역변수 1번을 오퍼랜드 스택에 입력(Push)
1: iload_2 # 지역변수 2번을 오퍼랜드 스택에 입력
2: iadd # 오퍼랜드 스택에서 두 꺼내어(Pop)을 꺼내어 더 한뒤 그 결과를 오퍼랜드 스택에 입력
3: istore_3 # 결과를 c에 저장
4: iload_3 # 리턴 값 꺼내기
5: ireturn # 리턴
LocalVariableTable:
Start Length Slot Name Signature
0 6 0 this LMyMain;
0 6 1 a I
0 6 2 b I
4 2 3 c I
여기서 a = 50, b = 20이라고 하면
출처 : Geeksforgeeks
마지막 ireturn을 실행하면 이전 프레임에게 결과값을 리턴하고 해당 프레임은 소멸된다.
일반적인 추상화란 중요한 특징을 찾아낸 후 간단하게 표현하는 것이다. 추상화는 여러가지 요소를 하나로 통합하는 방향성을 가지고 있다. 이는 문제를 여가지로 쪼개서 나눠보는 '문제 분할'과는 별개이다. 추상화를 이용하여 핵심적인 것만 남기게 되면 복잡한 내용도 한 눈에 알아볼 수 있어 이해하기 쉽다는 장점이 있다.
컴퓨터공학에서 추상화란 복잡한 자료, 모듈, 시스템에서 핵심적인 개념, 기능등을 간추려내는 것이다. 운영체제는 하드디스크는 파일, 네트워크에 대해 포트, 메모리에 대해 주소, CPU에 대해 프로세스라는 추상화된 방법을 제공한다.
객체지향에서 클래스 관련하여 추상화 요소를 찾아보자. 첫번째로 어떤 관념을 클래스를 정의하는 것 자체부터 추상화이다. 또한 여러 클래스간의 공통 속성/기능을 묶어 새로운 클래스를 정의하는 것도 추상화라고 볼 수있다. 예를 들어 개라는 관념을 Dog라는 클래스로 정의하는 것도 추상화이고, Dog 클래스와 Cat 클래스에서 공통된 기능을 묶어 Animal 클래스를 정의하는 것도 추상화이다. 즉 모든 클래스는 추상화를 통해 만들어진다. 인터페이스, 부모클래스를 정의하는 것은 클래스들을 추상화한 결과로 볼 수 있다.
캡슐화
연관 있는 것들을 하나로 묶어주는 것이 캡슐화이다. 연관있는 변수와 함수를 클래스로 묶고 외부에 감출내용은 감춘다. 잘 캡슐화(모듈화)되었다는 말은 연관있는 것들이 잘 응집되었다는 것이고 다른 모듈(객체, 클래스)와는 결합도가 낮아야 한다. 관심사의 분리, 낮은 결합도를 갖게하는 것이 목적이다.
상속
부모 클래스의 속성/기능은 자식 클래스에게 상속된다. 자식 클래스에서 따로 정의하지 않아도 부모 클래스에서 정의된 것들을 자동으로 상속받는 것이다. 상속을 통해 코드의 재사용성이 증가하여 기능을 확장하기 좋다.
다형성
서로 다른 방식을 하나의 표현으로 사용 할 수 있는 것이 다형성이다. 서로 다른 객체를 하나의 일반화된(추상화된) 클래스 혹은 메소드로 처리할 수 있는 것이다. 어떤 추상화된 객체를 사용하는 입장에서 그 객체가 실제로 무엇인지 몰라도 사용할 수 있어야 한다. 예를 들어 어떤 인터페이스를 사용한다고 할 때 그 인터페이스의 구현체가 무엇인지는 모른채로 사용할 수 있는 것이다. 객체간의 결합도를 낮추어 생산성과 유지보수성이 향상된다.
결론은 '관심사의 분리, 낮은 결합도, 코드의 재사용성'를 갖게하는 원리라고 볼 수 있다.
function test() {
console.log(test); // undefined 출력
var test = 'hello';
}
위 코드에서 test가 선언되기 전에 호출을 했음에도 오류가 나지 않는다. 다만 undefined 가 출력될 뿐이다. 이는 자바스크립트에서 함수 내에 선언된 변수/함수등을 최상단으로 끌어올려 선언하기 때문이다. 이를 호이스팅이라 한다.
즉 호이스팅이 일어나서 다음 코드와 동일하게 동작한다.
function test() {
var test;
console.log(test);
var test = 'hello';
}
function안의 변수들은 모두 선언 위치와 상관없이 function 내에서 scope를 유지하게 된다. 이를 function scope를 가진다고 한다.
처리방식
자바스크립트 Parser가 함수 실행전에 함수를 한번 훑어서 필요한 변수/함수 정보를 기억하고 있다가 실행한다.
코드 자체가 끌어올려지는 것은 아니고 Parser가 내부적으로 그렇게 처리하는 것이다.
때문에 실제 메모리에 변화는 없다.
호이스팅 대상
var로 선언된 변수/함수만 끌어올려지며 할당은 끌어올려지지 않는다. 즉 undefined 인 상태로 올려진다.
let/const, 함수표현식에선 호이스팅이 발생하지 않는다.
// 함수 선언문 - 호이스팅O (오류 안남, 콘솔로그 'myFunc' 출력됨)
function test() {
myFunc();
function myFunc() {
console.log('myFunc');
}
}
// 함수 표현식 - 호이스팅X (오류 발생 Uncaught TypeError: myFunc is not a function)
// myFunc은 undefined로 지정됨.
function test() {
myFunc();
var myFunc() = function() {
}
}
호이스팅 순서
동일 이름의 함수/변수가 있을 땐 '변수 선언 - 함수 선언 - 변수 할당' 순으로 진행된다.
function test() {
function hello() {
};
var hello = 'hello';
console.log(typeof hello);
}
호이스팅이 되면 다음 코드처럼 동작한다
function test() {
var hello;
function hello() {
};
hello = 'hello';
console.log(typeof hello); // 'string' 출력
}
중간에 변수 할당이 안일어 났다면
function test() {
var hello;
function hello() {
};
// hello = 'hello';
console.log(typeof hello); // 'function' 출력
}
알아두기
코드의 가독성과 유지보수를 위해 왠만하면 호이스팅이 안일어나게 하는게 좋다.
var을 사용하는 대신 ES6의 let/const를 사용한다.
var- function scope(호이스팅O), let/const- block scope(호이스팅X)
Publisher와 Subscriber가 독립적으로 데이터를 생산하고 소비한다. 프로듀서와 컴포넌트를 디커플링하기 위한 좋은 수단이다.
이런 느슨한 결합을 통해 둘 중 하나가 죽어도 서로간에 의존성이 없으므로 안정적으로 데이터를 처리할 수 있다.
리시버와 컬렉터의 통신을 API로 한다고 가정해보자.
컬렉터는 리시버가 요청한 것을 바로 처리해줘야 한다. (처리를 미룰 수 없다)
실패가 났을 때 부분 재처리가 불가능하다.
처리속도가 느린 컴포넌트 기준으로 처리량이 결정된다. 그러므로 트래픽이 몰리는 상황을 대비해 전체 파이프라인을 넉넉하게 산정해야 한다.
중간에 카프카를 두게 되면 이런게 좋아진다.
컬렉터는 리시버가 요청한 작업을 쌓아두고 나중에 처리할 수 있다.
실패가 나도 컬렉터만 따로 재처리 할 수 있다.
일시적으로 트래픽이 몰리는 상황을 대비해서 제일 프론트의 서버만 넉넉하게 준비해두면 된다. 물론 장기적이 되면 전체 파이프라인을 증설해야 겠지만.
또한 설정 역시 간단해진다.
Publisher 따로, Consume 따로 독립적으로 설정할 수 있다.
디스크 순차 저장 및 처리
메시지를 메모리큐에 적재하면 데이터 손실 가능성이 있지만 카프카는 디스크에 쓰므로 데이터 손실 걱정이 없다.
디스크에 쓰므로 상대적으로 속도가 느리지만, 순차처리 방식으로 디스크 I/O를 줄여 그렇게 느리지도 않다. 엄청 반응성이 높은 서비스가 아니라면 이 속도가 문제되진 않는다.
카프카 아키텍처 구성요소
토픽
카프카 안에는 여러 레코드 스트림이 있을 수 있고 각 스트림을 토픽이라고 부른다.
하나의 토픽에 대해 여러 Subscriber가 붙을 수 있다.
파티션
각 토픽마다 데이터를 여러개의 파티션에 나누어서 저장/처리한다.
토픽 사이즈가 커질 경우 파티션을 늘려서 스케일아웃을 할 수 있다.
일반적으로 브로커 하나당 파티션 하나다.
컨슈머 인스턴스 수는 파티션 갯수를 넘을 수 없다. 그러므로 병렬처리의 수준은 파티션 수에 의해 결정된다. 즉 파티션이 많을 수록 병렬처리 정도가 높아진다.
각 파티션마다 Publish되는 레코드에 고유 오프셋을 부여한다. 때문에 레코드는 파티션 내에서는 유니크하게 식별된다. 하지만 파티션간에는 순서를 보장하지 않는다.
전체 순서를 보장하고 싶으면 파티션을 하나만 두는 수 밖에 없는데, 이러면 데이터량이 많아져도 스케일아웃이 안되고, 컨슈머 인스턴스도 하나만 둘 수 있으므로 병렬 컨슈밍도 안된다.
데이터 보관기간
컨슘하고는 상관없다. 보관기간(Retention) 정책에 따른다.
데이터 사이즈가 늘어날지라도 성능은 일정하게 유지된다.
오프셋
일반적으로 컨슈머가 오프셋을 순차적으로 증가하며 컨슘해하지만, 원한다면 컨슈머 마음대로 조정할 수 있다. 재처리가 필요한 경우 오프셋을 이전으로 돌릴 수도 있고 가장 최근 레코드 부터 처리할 수도 있다.
컨슈밍 비용이 저렴하기 때문에 커맨드라인 컨슈머로 데이터를 "tail"하는 작업도 다른 컨슈머에 별 영향을 끼치지 않는다.
프로듀서
레코드를 프로듀스할 때 어느 토픽의 어느 파티션에 할당할 지를 결정한다.
일반적으로 라운드로빈 혹은 원하는 대로 할당방식을 지정할 수 도 있다.
컨슈머 그룹
컨슈머 그룹 마다 독립적인 컨슘 오프셋을 가진다.
컨슈머 그룹 내에서 처리해야할 파티션이 분배된다. 즉 하나의 파티션은 하나의 서버가 처리한다. 그룹에 서버가 추가되면 카프카 프로토콜에 의해 동적으로 파티션이 재분배 된다.
하나의 토픽 레코드를 분산처리하는 구조라면 동일 컨슈머 그룹을 가지게 해야 한다.
하나의 토픽 레코드에 각각 별도의 처리를 하는 다른 파이프라인이라면 서로 다른 컨슈머 그룹을 가지게 해야 한다.
큐(Queue)와 Pub/Sub의 혼합 모델
컨슈머그룹 내에서는 큐처럼 동작하고 컨슈머그룹간에는 Pub/Sub처럼 동작한다. 컨슈머그룹을 어떻게 두냐에 따라 두 방식 다 입맛에 맞게 선택할 수 있다.
데이터 순서 보장
일반적인 큐 모델에서 순차적으로 컨슘해간다고 해도 각 처리기에 도달하는 시간이 다르므로 순서가 보장되지 않는다.
그렇다고 처리기를 1개만 두면 병렬성이 떨어진다.
카프카는 토픽의 전체 순서는 보장하지 않지만 파티션별로는 처리 순서를 보장한다. (파티션은 하나의 컨슈머 인스턴스에서만 처리되므로). 즉 전체 순서 보장을 포기하고 부분 순서 보장을 취한 것이다. 대신 병렬성을 유지할 수 있다. 다르게 말하면 파티션당 컨슈머를 하나만 가져야하는 이유는 파티션 내에서 처리순서를 보장하기 위함이다.
데이터 복제
각 파티션을 여러대의 서버에 복제해둔다. 이는 설정값을 따른다. 크래시리포트는 ?개의 리플케이션을 두었다.
각 파티션 마다 특정 서버 한대를 리더로 선정하고 나머지 복제 파티션은 팔로워가 된다.
리더가 모든 읽기/쓰기를 처리한다. 리더는 요청을 패시브하게 팔로워들에게 전파한다.
각 서버는 하나의 리더 파티션을 갖는다. 때문에 트래픽은 각 서버로 밸런싱이 되는 셈이다.
복제 수가 N개라면 N-1개까지 죽어도 실패복구가 가능하다.
주키퍼의 역할
컨트롤러를 선출한다. 컨트롤러는 전체 파티션에 대한 리더/팔로워를 관리한다. 컨트롤러의 역할은 노드가 죽으면 다른 리플리카에게 리더가 되라고 명령을 내리는 역할을 한다.
어떤 브로커가 살아있는지를 체크한다.
어떤 토픽이 있고, 토픽에 파티션이 몇개 있고, 리플리카는 어디있고, 누가 리더가 될만한지, 각 토픽에 어떤 설정이 되어있는지를 관리한다.
오프셋 관리
카프카에서 관리하는 오프셋은 두 종류가 있다.
Current Offset : 컨슈머에게 전송된 마지막 레코드의 포인터
Committed Offset : 컨슈머가 성공적으로 처리한 마지막 레코드의 포인터.
오프셋 커밋 방법
카프카에서 관리되는 방식 : _consumer_offsets 토픽에 오프셋이 저장된다.
오토 커밋 : 일정 주기를 가지고 자동으로 커밋한다. 작업이 끝났든 안끝났든 주기만 되면 커밋한다.
커밋되기 전에 리밸런싱이되면 중복처리가 발생한다.
처리 완료되기 전에 커밋 후 프로세스가 죽으면 데이터 손실이 발생한다. (at-least-once 보장X)
수동 커밋 : 수동으로 커밋 API를 호출한다. 정확히 작업이 끝나고 커밋하는 걸 보증하기 위해 사용한다.
커밋되기 전에 리밸런싱되면 중복처리가 발생한다.
자체적으로 관리하는 방식 : 별도 DB등에 자체적으로 오프셋을 관리한다.
메시지 보증 전략
일반적인 보증 전략은 다음과 같고 카프카는 at-least-once로 보증한다.
at-most-once : 중복X, 유실O
exactly-once : 중복X, 유실X, 구현하기 어렵다.(비용이 비싸다)
at-least-once : 중복O, 유실X
데이터가 중복되는 경우는 다음과 같다. 어떤 데이터가 poll됐으나 commit되지 않은 시점에 리밸런싱 작업이 일어나면 이미 poll되어서 처리중인 데이터를 다른 컨슈머가 또 poll갈 수 있다.
수동 커밋에서도 마찬가지다. 커밋 전에 리밸런싱이 되는 경우 중복으로 처리될 수 있다.
가장 좋은건 exactly-once지만 비용이 비싸므로 적당한 타협지점은 at-least-once이다.중복되는 메시지는 메시지 ID나 시간등으로 어느정도 보정이 가능하기 때문이다.
카프카 0.11 버전 부터 idempotent producer와 tracsaction producer의 등장으로 exactly-once를 보장할 수 있다고 한다.
내부적으론 레코드의유니크ID, 트랜잭션ID, 프로듀서ID등을 조합해서 처리한다고 한다.
크래시리포트의 오프셋 관리
스파크 클러스터만 수동커밋을 하고 있다. 스파크는 보통 poll에서 프로세싱 완료까지 시간이 오래걸릴 것으로 예상되므로 오토커밋을 할 경우 데이터 손실 가능성이 커서 수동으로 커밋하는 걸로 보인다.
오프셋을 카프카가 아닌 별도의 DB에 저장했다. commitAsync()에서 fail이 발생했던 거 같은데 정확한 원인은 모르겠다.
다른 미들웨어와 비교해보자.
RabbitMQ
장점
다양한 기능, 높은 성숙도
20k/sec 처리 보장
Kafka
장점
고성능 고가용성
분산처리에 효과적으로 설계됨
100k/sec 처리 보장
겪었던 이슈들
ERROR [Thread-20] [Consumer clientId=consumer-13, groupId=xxx-collector] Offset commit failed on partition zxx.topic-1 at offset 199: The request timed out.